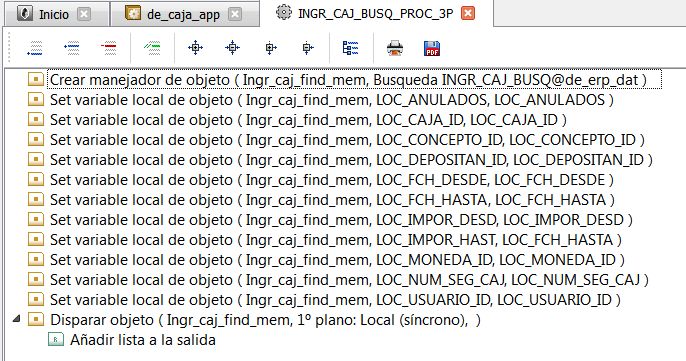
Aclaro que por supuesto que he leído la documentación, y por eso mismo mi planteo. Adjunto las 3 imagenes puesta en la idea, para aclarar mi tema.
Si bien la idea se llama
Carga de listas, proceso optimizado para la nube POR DEFAULT. en los comentarios de la idea se explica este tema de busqueda, y la idea tiene 15 votos ademas del mio, es decir, al menos 15 personas entienden cual es el problema y les importa (y me siguen pareciendo demasiado pocos. que solo 15 personas armen estas busquedas y no les importe estar poniendo estas lineas una y otra vez, al no poderse usar bien el ‘pegar como’).
@aztecmexico, dices yo creo que ya deberías dejar de comparar lo que haces en otras plataformas con lo que haces en V7, porque solo sufres, y esto es simple, si SQL tiene vistas, funciona en 3er plano por defecto, y miles de otras monerías pues yo me pregunto, ¿Porqué no háce el desarrollo en esa plataforma?
Por si acaso, tengo desarrollos en otras plataformas, y justamente por estos temas, Velneo ha quedado utilizado en pocos proyectos, y aun no renuevo N3, que use 3 gestiones, a pesar del poco uso, pero ahora he decidido esperar, la menos hasta ver si hay promeso de arreglo en temas tan básicos como las búsquedas, entre otras cosas.
El problema es que ya tengo desarrollos hechos, y no es aceptable para mi que cada nueva búsqueda que me pidan, tenga que otra vez estar con los tropecientos SET y GET. Como dije, mi peticiones no son nada del otro mundo, es algo que es estandar, y que ni siquiera implicaria demasiada complejidad, segun lo que conozco de C++. La idea es que los creadores de cualquier herramienta lo hagan una sola vez, y el resto evite repetir los chorrocientos SET y GET cada vez que quiera hacer una busqueda medianamente compleja y quiera buen rendimiento WAN.
Y Alfonso, no es un tema de que se desconozca como funcionan las búsquedas, eso se conoce bien, es un tema de que el objeto búsqueda, por cientos de componentes que tenga, no tiene justificativo logico alguno el hacer esos viajes de ida y vuelta entre el cliente y servidor, un viaje por cada componente de búsqueda.
Por cientos de componentes que le pongan a una búsqueda, el viaje entre el cliente y el servidor, debe ser UNO SOLO, esto te lo dice hasta un estudiante de ingeniería de software (me he tomado la molestia de comprobarlo en persona), porque eso es lógica básica, hay que evitar saturar innecesariamente la conexión de red, especialmente cuando estamos en WAN.